Para empezar recordemos una de las generalizaciones dadas para la suma geométrica. Una revisión detallada de cómo se deduce esta identidad se puede encontrar en el PDF. Linealidad de la iteración del operador y sus aplicaciones en la suma geométrica se sugiere solamente como contexto. No es relevante para la aplicación que mostraremos a continuación.
Observación 6.1 Sean 

Para los lectores familiarizados con términos de probabilidad, es sencillo entender la aplicación de la identidad anterior. Esta identidad tiene relevancia en los conceptos de distribución binomial negativa. Sin embargo, en este sitio, lo que se busca es hacer asequibles los conceptos que se presentan para todos. Por eso, revisaremos superficialmente algunos conceptos de probabilidad. Esto facilitará el entendimiento de lo que se pretende mostrar. Cabe mencionar que en el ejemplo principal se utilizará el número de visitantes del sitio. Hasta el momento de publicar esta entrada, este número es (1863). Por suerte para los ejemplos, el número es mayor a cero.
Experimentos tipo Bernoulli
Recordemos que un experimento tipo Bernoulli es un experimento aleatorio. No podemos determinar su resultado y tiene exactamente dos posibles resultados. Estos resultados se identifican normalmente como «éxito» o «fracaso». Comúnmente, se denota la probabilidad de que suceda un «éxito» con la letra 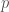







Algunas distribuciones discretas
Ahora, retomaremos algunas nociones básicas de distribuciones para poder revisar como se relaciona la identidad de la Observación 6.1 con la distribución binomial negativa. En lo siguiente se entenderá que se trabaja sobre una secuencia de experimentos Bernoulli que suceden con las mismas condiciones, es decir, que la probabilidad asignada a cada uno de sus posibles resultados es la misma para cada experimento y que la secuencia de experimentos son independientes, es decir que los resultados de un experimento dado no están determinados por algún otro experimento.
Observación 6.2 Sean 

i)

ii)

iii)

iv)

Con lo anterior recordemos que,
1)
Distribución uniforme discreta
Dada una variable aleatoria 

![P [ X = x_i ]= \left\lbrace \begin{aligned} \dfrac{1}{n} \hspace{2.5cm} & x_i \in \left\lbrace x_1, ... , x_n \right\rbrace , \\ \\ 0 \hspace{2.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+x_i+%5D%3D++%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+%5Cdfrac%7B1%7D%7Bn%7D+++%5Chspace%7B2.5cm%7D+%26+x_i+%5Cin+%5Cleft%5Clbrace+x_1%2C+...+%2C+x_n+%5Cright%5Crbrace+%2C+%5C%5C+%5C%5C+0++%5Chspace%7B2.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Ejemplo: la probabilidad de que un visitante lea esta entrada del blog es de 
2)
Distribución binomial
Dada una secuencia de experimentos Bernoulli independientes, la distribución binomial 



![P [ X = r ]= \left\lbrace \begin{aligned} \binom{n}{r} p^r (1- p )^{n-r} \hspace{0.5cm} & 0 \leq r \leq n , \\ \\ 0 \hspace{3cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+r+%5D%3D++%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+%5Cbinom%7Bn%7D%7Br%7D+p%5Er+%281-+p+%29%5E%7Bn-r%7D+%5Chspace%7B0.5cm%7D+%26+0+%5Cleq+r+%5Cleq+n++%2C+%5C%5C+%5C%5C+0++%5Chspace%7B3cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Ejemplo: la probabilidad de que 308 visitantes lean una entrada del blog es de ![\begin{aligned} P [ X = 308]&= \binom{1863}{308} \left( {{1}\over{6}} \right)^{308} \left(1- {{1}\over{6}} \right)^{1863-308} \\&=\binom{1863}{308} \left( {{1}\over{6}} \right)^{308} \left( {{5}\over{6}} \right)^{1555} \approx 0.03152 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+P+%5B+X+%3D+308%5D%26%3D+%5Cbinom%7B1863%7D%7B308%7D+%5Cleft%28+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7B308%7D+%5Cleft%281-+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7B1863-308%7D++%5C%5C%26%3D%5Cbinom%7B1863%7D%7B308%7D+%5Cleft%28+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7B308%7D+%5Cleft%28+%7B%7B5%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7B1555%7D+%5Capprox++0.03152+++%5Cend%7Baligned%7D+&bg=FFFFFF&fg=444444&s=0&c=20201002)

3)
Distribución geométrica
Dada una secuencia de experimentos Bernoulli independientes con una probabilidad constante 

![P [ X = x]= \left\lbrace \begin{aligned} p (1- p )^{x-1} \hspace{2.5cm} & x=1, 2, 3, \cdots \hspace{0.5cm} (\textit{para experimentos }) \\ \\ 0 \hspace{3.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+x%5D%3D+%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+p+%281-+p+%29%5E%7Bx-1%7D+%5Chspace%7B2.5cm%7D+%26++x%3D1%2C+2%2C+3%2C+%5Ccdots+%5Chspace%7B0.5cm%7D+%28%5Ctextit%7Bpara+experimentos+%7D%29+%5C%5C+%5C%5C+0+%5Chspace%7B3.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.+&bg=FFFFFF&fg=444444&s=0&c=20201002)
![P [ X = k]= \left\lbrace \begin{aligned} p (1- p )^{k} \hspace{2.5cm} & k= 0, 1, 2, \cdots \hspace{0.5cm} ( \textit{para fracasos}) \\ \\ 0 \hspace{3.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+k%5D%3D+%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+p+%281-+p+%29%5E%7Bk%7D+%5Chspace%7B2.5cm%7D+%26+k%3D+0%2C+1%2C+2%2C+%5Ccdots+%5Chspace%7B0.5cm%7D+%28++%5Ctextit%7Bpara+fracasos%7D%29+%5C%5C+%5C%5C+0+%5Chspace%7B3.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Ejemplo: La probabilidad de que el quinto visitante haya sido el primero en leer una entrada del blog es de
![P [ X = 5]= \left( {{1}\over{6}} \right) \left(1- {{1}\over{6}} \right)^{5-1} \approx 0.0803](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+5%5D%3D+%5Cleft%28+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29+%5Cleft%281-+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7B5-1%7D+%5Capprox+0.0803+&bg=FFFFFF&fg=444444&s=0&c=20201002)
4)
Distribución binomial negativa
Dada una secuencia de experimentos Bernoulli independientes con una probabilidad constante 

![P [ X = x ]= \left\lbrace \begin{aligned} \binom{x-1}{r-1} p^r (1- p )^{x-r} \hspace{1cm}& x=r, r+1, +r+2, \cdots \\ \\ 0 \hspace{3.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+x+%5D%3D+%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+%5Cbinom%7Bx-1%7D%7Br-1%7D+p%5Er+%281-+p+%29%5E%7Bx-r%7D+%5Chspace%7B1cm%7D%26++x%3Dr%2C+r%2B1%2C+%2Br%2B2%2C+%5Ccdots+%5C%5C+%5C%5C+0+%5Chspace%7B3.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Para «fracasos»,
![P [ X = k ]= \left\lbrace \begin{aligned} \binom{k+r-1}{k} p^r (1- p )^{k} \hspace{1cm} & k=0, 1, 2, \cdots \\ \\ 0 \hspace{3.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+k+%5D%3D+%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+%5Cbinom%7Bk%2Br-1%7D%7Bk%7D+p%5Er+%281-+p+%29%5E%7Bk%7D+%5Chspace%7B1cm%7D+%26+k%3D0%2C+1%2C+2%2C+%5Ccdots+%5C%5C+%5C%5C+0+%5Chspace%7B3.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Ejemplo: La probabilidad de que en la visita 

![P [ X = 211]=\binom{211-1}{4-1} \left( {{1}\over{6}} \right)^{4} \left(1- {{1}\over{1863}} \right)^{211-4}\approx 7.943X10^{-13}](https://s0.wp.com/latex.php?latex=P+%5B+X+%3D+211%5D%3D%5Cbinom%7B211-1%7D%7B4-1%7D+%5Cleft%28+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7B4%7D+%5Cleft%281-+%7B%7B1%7D%5Cover%7B1863%7D%7D+%5Cright%29%5E%7B211-4%7D%5Capprox+7.943X10%5E%7B-13%7D+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Análisis sobre «éxitos» y «fracasos» en la distribución binomial negativa; relación de complementariedad
Ahora que ya conocemos los términos adecuados sobre la distribución binomial negativa, vamos a plantear la aplicación en la teoría de probabilidades de la identidad mostrada en la Observación 6.1. Primero hagamos un paréntesis para revisar un par de hechos sobre particiones naturales para entender el contexto del objetivo.
Observación 6.3
a) Supongamos que 






b) 




En particular, si 




Solamente se uso el cambio de variable 


![P [ X =r+(k-1)]= \left\lbrace \begin{aligned} \binom{k+r-2}{k-1} p^r (1- p )^{k-1} \hspace{1cm} & r, k= 1, 2, 3, \cdots \\ \\ 0 \hspace{3.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B++X+%3Dr%2B%28k-1%29%5D%3D+%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+%5Cbinom%7Bk%2Br-2%7D%7Bk-1%7D+p%5Er+%281-+p+%29%5E%7Bk-1%7D+%5Chspace%7B1cm%7D+%26+r%2C+k%3D+1%2C+2%2C+3%2C+%5Ccdots+%5C%5C+%5C%5C+0+%5Chspace%7B3.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.&bg=FFFFFF&fg=444444&s=0&c=20201002)
Esta función cuenta el número total de experimentos hasta r éxitos. Análogamente, sabemos que modelar «éxitos» o «fracasos» son complementarios en
![P [ X =k+( r-1)]= \left\lbrace \begin{aligned} \binom{k+r-2}{r-1}(1- p)^k p ^{r-1} \hspace{1cm} & r, k = 1, 2, 3, \cdots \\ \\ 0 \hspace{3.5cm} & \textit {en otro caso }. \end{aligned} \right.](https://s0.wp.com/latex.php?latex=P+%5B++X+%3Dk%2B%28+r-1%29%5D%3D+%5Cleft%5Clbrace+%5Cbegin%7Baligned%7D+%5Cbinom%7Bk%2Br-2%7D%7Br-1%7D%281-+p%29%5Ek+p+%5E%7Br-1%7D+%5Chspace%7B1cm%7D+%26++r%2C+k+%3D+1%2C+2%2C+3%2C+%5Ccdots+%5C%5C+%5C%5C+0+%5Chspace%7B3.5cm%7D+%26+%5Ctextit+%7Ben+otro+caso+%7D.+%5Cend%7Baligned%7D+%5Cright.&bg=FFFFFF&fg=444444&s=0&c=20201002)
Y aquí es cuando la magia sucede, usando la identidad de la Observación 6.1 y tomando las probabilidades durante los recorridos de los valores 

Es sencillo verificar las implicaciones que tiene esta identidad en la teoría probabilidad, veamos un ejemplo.
Ejemplo: Supongamos nos interesa modelar hasta que visita 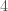




![\begin{aligned} g(X) =P[X=4+(k-1)]&=\binom{X-1}{4-1} {\left({{1}\over{6}}\right)}^4 \left(1- {{1}\over{6}} \right)^{X-4} \\ &=\binom{k+2}{k-1} {\left({{1}\over{6}}\right)}^4 \left(1- {{1}\over{6}} \right)^{k-1} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+g%28X%29+%3DP%5BX%3D4%2B%28k-1%29%5D%26%3D%5Cbinom%7BX-1%7D%7B4-1%7D+%7B%5Cleft%28%7B%7B1%7D%5Cover%7B6%7D%7D%5Cright%29%7D%5E4+%5Cleft%281-+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7BX-4%7D+%5C%5C+%26%3D%5Cbinom%7Bk%2B2%7D%7Bk-1%7D+%7B%5Cleft%28%7B%7B1%7D%5Cover%7B6%7D%7D%5Cright%29%7D%5E4+%5Cleft%281-+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7Bk-1%7D+%5Cend%7Baligned%7D&bg=FFFFFF&fg=444444&s=0&c=20201002)
La cuestión se pone interesante, sí quisiéramos saber la probabilidad que en un máximo de 
![\begin{aligned} P[4 \leq X \leq 1500] &= \displaystyle\sum_{k=4}^{1500} g(X)\\&=\displaystyle\sum_{k=1}^{1497} \binom{k+2}{k-1} {\left({{1}\over{6}}\right)}^4 \left(1- {{1}\over{6}} \right)^{k-1} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+P%5B4+%5Cleq+X+%5Cleq+1500%5D+%26%3D+%5Cdisplaystyle%5Csum_%7Bk%3D4%7D%5E%7B1500%7D+g%28X%29%5C%5C%26%3D%5Cdisplaystyle%5Csum_%7Bk%3D1%7D%5E%7B1497%7D+%5Cbinom%7Bk%2B2%7D%7Bk-1%7D+%7B%5Cleft%28%7B%7B1%7D%5Cover%7B6%7D%7D%5Cright%29%7D%5E4+%5Cleft%281-+%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7Bk-1%7D+%5Cend%7Baligned%7D&bg=FFFFFF&fg=444444&s=0&c=20201002)
Pero conociendo la relación de complementariedad de los «éxitos» y de los «fracasos» aplicada en la probabilidad acumulada entonces tenemos que,
![P[4 \leq X \leq 1500] =1- \displaystyle\sum_{r=1}^{4} \binom{1495 +r }{r-1} {\left(1-{{1}\over{6}}\right)}^{1497} \left({{1}\over{6}} \right)^{r-1}](https://s0.wp.com/latex.php?latex=P%5B4+%5Cleq+X+%5Cleq+1500%5D+%3D1-+%5Cdisplaystyle%5Csum_%7Br%3D1%7D%5E%7B4%7D+%5Cbinom%7B1495+%2Br+%7D%7Br-1%7D+%7B%5Cleft%281-%7B%7B1%7D%5Cover%7B6%7D%7D%5Cright%29%7D%5E%7B1497%7D+%5Cleft%28%7B%7B1%7D%5Cover%7B6%7D%7D+%5Cright%29%5E%7Br-1%7D+&bg=FFFFFF&fg=444444&s=0&c=20201002)
Por lo tanto,
![P[4 \leq X \leq 1500] \approx 0.009255](https://s0.wp.com/latex.php?latex=P%5B4+%5Cleq+X+%5Cleq+1500%5D+%5Capprox+0.009255&bg=FFFFFF&fg=444444&s=0&c=20201002)
Como se puede apreciar, no es necesario ser un experto en el tema de las probabilidades para poder visualizar las aplicaciones de las identidades que surge usando la propiedad iterativa del operador Suma, es suficiente con dejar volar la imaginación pues la grandeza de las matemáticas hace que de alguna u otra forma los resultados de las disciplinas matemáticas converjan. Para finalizar esta entrada mostraremos la propiedad inmediata que surge en la relación de complementariedad y la distribución beta.
Relación de complementariedad para la distribución beta y otras identidades.
Como ya estamos habituados con términos de probabilidad esta sección se hará lo más breve posible, sólo recordaremos algunos conceptos y utilizaremos la identidad de la Observación 6.1. Comenzaremos recordando la definición usual de la función beta.
Definición 7.1 



Por otra parte, retomando la identidad finita de la Observación 6.1 sabemos que, sí 

Y manipulando la identidad anterior usando el cambio de variable 

Entonces, sustituyendo valores en la identidad anterior se sigue que,

Y como se está usando un cambio de variable,
Por lo tanto, usando la identidad anterior, integración y las propiedades de la función beta podemos ver lo siguiente .

Observación 7.2 Sean 

1)

2)

3)

4)

De igual forma que en el apartado anterior, las funciones de distribución son los sumandos de las identidades anteriores y las aplicaciones son de carácter inmediato.
